In the intricate web of internet navigation, where search engines are both gatekeepers and guides, the Meta Robots tag emerges as an unsung hero—a small line of code wielding significant power over how content is perceived and indexed. As website owners, developers, and marketers strive for perfection in their digital strategy, understanding this seemingly simple HTML element can unlock the door to greater control and visibility in an increasingly competitive online landscape. In this guide, we will delve into the world of the Meta Robots tag, exploring its various functionalities, best practices, and the nuances that can enhance your siteS performance in the ever-evolving realm of search engine optimization. Join us as we demystify this essential tool, empowering you to navigate and ultimately harness the potential of the web with confidence and clarity.
Table of Contents
- Understanding the Meta Robots Tag and Its Importance for SEO
- Mastering the Different Directives: Indexing, Following, and Beyond
- Common Missteps with Meta Robots Tags and How to Avoid Them
- Best Practices for Implementing Meta Robots Tags on Your Website
- Q&A
- Final Thoughts
Understanding the Meta Robots Tag and Its Importance for SEO
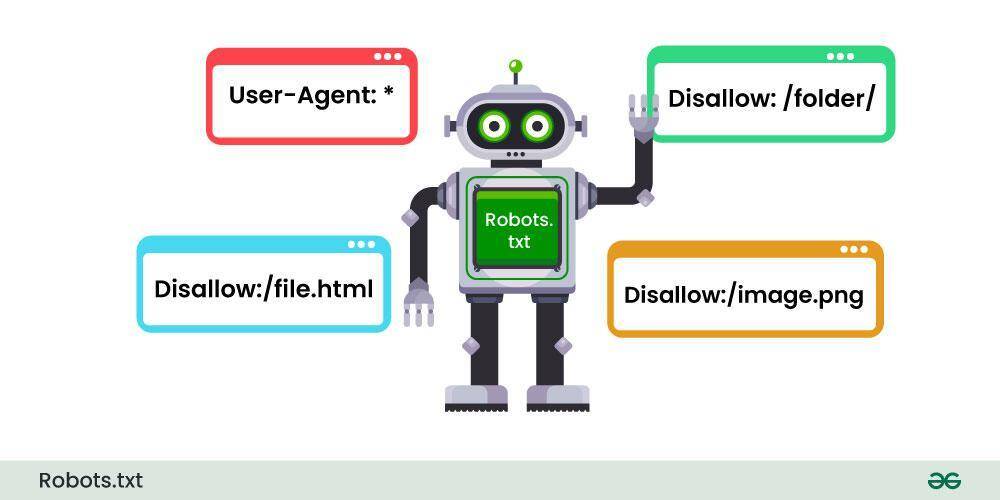
The Meta robots Tag offers webmasters an essential tool for tailoring how search engines interact with their content. By incorporating this tag within the HTML of a webpage, website owners can communicate specific instructions to search engine crawlers. This capability allows for granular control over which pages should be indexed or followed, offering a strategic advantage in managing site visibility. Common directives include:
- index: Allowing the page to be indexed.
- noindex: Preventing the page from being indexed.
- follow: Allowing links on the page to be followed.
- nofollow: Instructing that links on the page should not be followed.
The correct use of the Meta robots Tag not only optimizes a site for search engines but also enhances user experience by guiding crawlers through the most relevant content. Understanding the implications of each directive is critical as improper use can lead to unintentional consequences, such as critically important pages being excluded from search results. Here’s a simple table illustrating some common directives and their impact:
| Directive | Effect |
|---|---|
| index, follow | Page can be indexed and links are followed |
| noindex, follow | Page will not be indexed, but links will be followed |
| index, nofollow | Page can be indexed, but links will not be followed |
| noindex, nofollow | Page will not be indexed and links will not be followed |
By leveraging the capabilities of the Meta Robots Tag, website owners can strategically enhance their SEO efforts while maintaining greater control over how their content is presented in search results. Implementing this tag wisely helps ensure that a website aligns closely with its traffic and visibility goals,illustrating the importance of thoughtful site management in today’s crowded digital landscape.
Mastering the Different Directives: Indexing, Following, and Beyond
The world of the meta robots tag is akin to a finely tuned orchestra, where each directive contributes to the performance of your website in the search engine landscape. The most common directives you’ll encounter are index, noindex, follow, and nofollow.When you want search engines to include a page in their indices while also inviting them to crawl linked content, you’d use index, follow. Conversely, if you wish to keep specific pages out of the navigable realm of search results, noindex preserves your content while maintaining the integrity of your internal linking structure. Understanding the nuances of these commands is vital for any web administrator aiming to control their site’s visibility effectively.
Beyond these standard directives, you may also explore the utility of other lesser-known commands. As an example, noarchive can prevent search engines from saving a cached copy of your page, which is useful for dynamic content that changes frequently. To illustrate how these directives work together, consider the following table:
| Directive | description | Use Case |
|---|---|---|
index |
Allows the page to be indexed by search engines | Standard content pages |
noindex |
Prevents the page from being indexed | Thank you pages or duplicate content |
follow |
Enables links on the page to be followed for indexing | Link-rich pages |
nofollow |
Disallows search engines from following links on the page | Sponsored or user-generated content |
By mastering these directives and understanding their strategic applications, you can better tailor your site’s interaction with search engines. The adaptability offered by meta robots tags allows you to orchestrate a harmonious balance between visibility and control, ensuring that your web presence reflects your intentions.
Common missteps with Meta Robots Tags and How to Avoid them
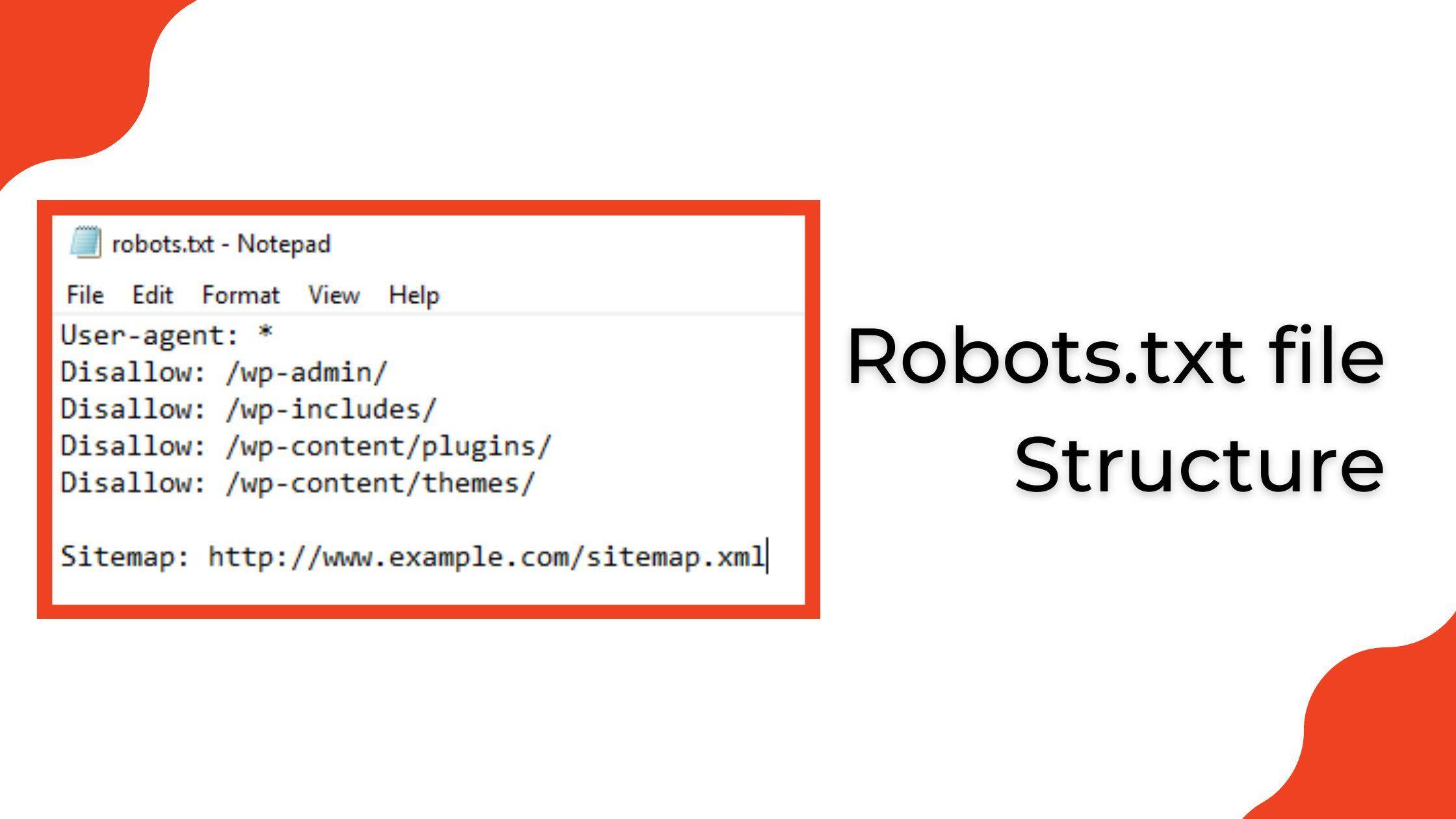
When managing your website’s visibility to search engines, using meta robots tags can be a powerful tool, but common errors can undermine their effectiveness. One prevalent mistake is overlooking the order of directives. The placement of “noindex” and “nofollow” can lead to mixed signals for search engine crawlers. Additionally, many webmasters neglect to appropriately use the robots.txt file in conjunction with meta tags, which can result in unintended content being indexed or inadvertently blocking access to essential pages. Ensure your directives are clearly defined and check your robots.txt file for compatibility.
Another frequent misstep involves the incorrect implementation of meta tags across different templates, causing inconsistencies in how pages are indexed. Uniformity is key; if some pages use “index, follow” while others are set to “noindex,” the end result can confuse search engine algorithms.consider the following best practices to maintain cohesion:
| Best Practices | Details |
|---|---|
| Standardize tags | Ensure all pages follow the same directive structure. |
| Regular Audits | Conduct periodic reviews to identify and resolve discrepancies. |
| Test Changes | Utilize testing tools to see real-time impacts of tag changes. |
Best Practices for Implementing Meta Robots Tags on Your Website
When implementing meta robots tags on your website, it’s essential to follow specific best practices to maximize their effectiveness without compromising user experience. Start by ensuring that you use unique tags for each page, as this helps search engines understand your intentions more clearly. Avoid using conflicting tags, such as noindex and index together, which can confuse crawlers. As an example,if a page contains useful content but is not intended for public view,use noindex along with nofollow to instruct search engines to avoid indexing the page while still allowing link evaluation.
Additionally, it’s crucial to test the implementation of meta robots tags across different browsers and devices to ensure they function as intended.Using tools like Google Search Console can provide insights into how search engines are interpreting these tags on your site. You may also consider creating a thorough strategy that includes the following points:
- Consistent monitoring and updating of tags as your content evolves.
- Clear documentation of which pages have specific tags and why.
- Using sitemap XML files that clearly delineate which pages should be indexed.
| Tag | Use Case |
|---|---|
| index, follow | Standard pages you want indexed. |
| noindex | Content you want to exclude from search. |
| nofollow | Links that shouldn’t be followed. |
Q&A
Q&A: Unlocking the Meta Robots Tag: A Guide to Web Control
Q1: What is the Meta Robots Tag, and why is it critically important? A1: The Meta robots Tag is a snippet of HTML code that tells search engines how to crawl and index a website’s content. It’s essential because it gives webmasters control over their site’s visibility: whether to allow search engines to index a page, follow links, or even prevent certain content from being seen.This ensures that sensitive or duplicate content doesn’t clutter search results, helping guide users to the most relevant pages.
Q2: How can I implement the Meta Robots Tag on my website? A2: Implementing the Meta Robots tag is relatively straightforward. You simply insert the tag inside the section of your HTML.The syntax looks like this: . You can customize the content attribute based on your needs—using directives like ‘index’, ‘noindex’, ‘follow’, or ‘nofollow’ to control how your pages are crawled.
Q3: What are some common directives found in the Meta Robots tag? A3: Some of the most common directives are:
- index: allows search engines to include the page in search results.
- noindex: Prevents search engines from indexing the page.
- follow: Allows search engines to follow the links on the page.
- nofollow: Tells search engines not to follow the links.
You can combine directives like this: to achieve specific goals.
Q4: Can the Meta robots Tag impact my website’s SEO? A4: Absolutely. The Meta Robots Tag plays a crucial role in SEO strategies. Using it properly can help improve the quality of your site’s indexation, prevent duplicate content issues, and enhance user experience by ensuring users find the right content.conversely, incorrect use could lead to valuable pages being deindexed or hidden from search engines, potentially harming your visibility.
Q5: Are there any alternatives to the Meta Robots Tag for controlling indexing? A5: Yes! While the Meta Robots Tag is one effective method, you can also use the robots.txt file to manage crawler access on a broader scale. This file gives instructions on which parts of your site can be crawled and indexed. Additionally, you can employ X-Robots-Tag HTTP headers for more granular control over specific file types (like pdfs). Both methods can complement the Meta Robots Tag.
Q6: What mistakes should I avoid when using the Meta Robots tag? A6: A few common pitfalls include:
- Overusing ‘noindex’: Being overly restrictive can prevent critically important pages from appearing in search results.
- Inconsistent use across similar pages: Inconsistencies can confuse search engines and dilute content relevance.
- Neglecting to test changes: Always verify your implementation with tools like Google Search Console to ensure your directives are being followed as intended.
Q7: How can I check if my Meta Robots Tag is working properly? A7: Checking your Meta Robots Tag’s functionality is key for maintaining control over your site. Use Google Search Console to see how Google indexes your pages. You can also inspect the page source in your web browser (right-click and select ‘View Page Source’) to ensure your tags are correctly implemented. Tools like Screaming frog can also help analyze and audit your site’s robot directives at scale.
Q8: Any final tips for effectively using the Meta Robots Tag? A8: Yes! it’s crucial to have a clear strategy for using the Meta robots Tag. Define your goals for individual pages and document your tagging practices. Regularly review and adjust your tags based on changing content or site structure. Keep learning about search engine behavior and stay updated on SEO trends,as this will help you adapt and optimize your web control methods effectively. — With this guide, you’re well on your way to mastering the meta Robots Tag and unlocking the full potential of your web control!
Final Thoughts
As we conclude our exploration of the often-overlooked Meta Robots Tag, it’s clear that the power to manage your website’s visibility and indexing lies quite literally at your fingertips. By understanding and implementing this simple yet effective tool, you can guide search engines in their journey through your digital landscape, ensuring that your content reaches the audience it deserves while keeping unruly elements at bay. As you embark on your web optimization endeavors, remember that each tag is a step toward mastering the intricate dance of SEO. Whether you choose to follow, index, nofollow, or noindex, you are taking control of your online narrative. Embrace the flexibility and creativity that the Meta Robots Tag affords, and let it be a beacon guiding your web strategy. In the ever-evolving world of digital marketing, informed decisions are your greatest allies. So, unlock the potential of the Meta Robots Tag, and carve out your space in the vastness of the web with confidence and clarity. Your audience awaits, and with the right tools, you can ensure they find exactly what they’re looking for.