In the vast,intricate landscape of the internet,where websites are akin to bustling cities filled with details and activity,there lies a quiet but powerful gatekeeper: the robots.txt file. Often overlooked by the casual user, this small text file holds the key to understanding how search engines and web crawlers navigate the labyrinthine web. As we dive deep into the heart of web management, “Unlocking Web Secrets: The Role of robots.txt Explained” will explore the importance of this seemingly simple tool. Together, we will unravel the layers of control it offers to website owners, the implications for SEO, and the delicate balance it strikes between visibility and privacy. Join us as we bring clarity to the role of robots.txt and investigate how it shapes our online experiences.
Table of Contents
- Understanding the Basics of Robots.txt and Its Importance for Web Crawlers
- Navigating the Intricacies: How Robots.txt Controls Search Engine Behavior
- best Practices for Crafting an Effective Robots.txt File
- Common Pitfalls to Avoid When Using Robots.txt for SEO Optimization
- Q&A
- In Conclusion

Understanding the Basics of Robots.txt and Its Importance for Web Crawlers
In the vast expanse of the internet, the robots.txt file serves as the digital equivalent of a “Do Not Disturb” sign for web crawlers. This simple text file, placed in the root directory of a website, dictates which parts of the site can be indexed by search engines and which parts should remain hidden away, inaccessible to automated bots. By implementing rules within this file, website administrators possess the power to guide search engine crawlers, ensuring that only the most relevant content is showcased in search results. This aspect is pivotal because it can substantially influence a site’s visibility and, ultimately, its traffic.
Understanding how to effectively use robots.txt not only boosts a website’s performance but also protects sensitive information.A well-structured file might include a variety of directives, such as:
- User-agent: Specifies which web crawlers the rules apply to.
- Disallow: Indicates sections of the site that bots should not access.
- Allow: Permits access to certain pages within restricted sections.
The combination of these directives creates a balance between usability and privacy.As a notable example, a carefully crafted robots.txt file can prevent search engines from indexing non-essential pages, thereby ensuring that only quality content attracts attention:
| Directory | Access |
|---|---|
| /private | No access |
| /blog | Allowed |
| /images | No Access |
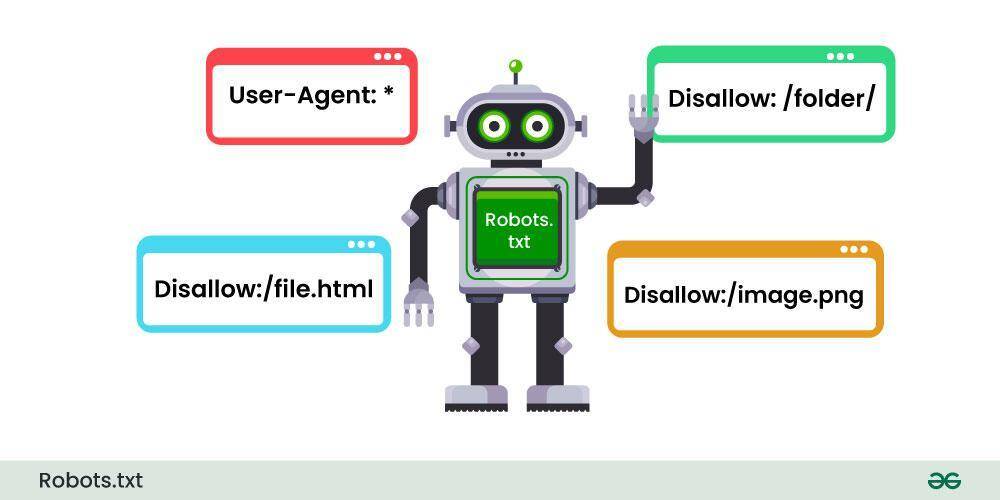
Navigating the Intricacies: How Robots.txt Controls Search Engine Behavior
The robots.txt file acts as a gatekeeper for your website, guiding search engine crawlers on what content to explore and what to avoid. This simple text file exists in the root directory of your website, serving as a dialog line between you and the various search engines. By configuring this file, webmasters can dictate critically important aspects of search engine behavior, including which pages to index, which to drop, and even how to prioritize site exploration. It’s crucial to get it right, as an incorrectly configured robots.txt file can lead to unintended consequences, such as critical pages being de-indexed or important content being ignored by search engines.
Within the realm of search engine optimization, understanding the syntax and directives of the robots.txt file is favorable. Here are some common directives you might encounter:
- User-agent: Specifies the web crawler to which the rule applies.
- Disallow: Tells the crawler which pages or sections to avoid.
- Allow: Permits access to specific pages even if a parent directory is disallowed.
| Directive | Description |
|---|---|
| User-agent | Identifies the crawler implementing the rules. |
| Disallow | Prevents specified pages from being crawled. |
| Allow | Lets crawlers access specific pages within a disallowed parent. |
Utilizing these directives effectively bolsters your SEO strategy, ensuring that search engines focus on your most vital content while keeping less relevant pages out of the indexing process.Remember, communication is key; being precise with your commands will help align search engine behavior with your website goals, allowing you to unlock the full potential of your online presence.
best Practices for Crafting an Effective Robots.txt File
When drafting your robots.txt file, clarity and precision are paramount. The User-agent directive specifies which web crawlers the rules apply to, and you must ensure you are targeting them correctly. It’s wise to utilize the asterisk () to create broad permissions or restrictions when you’re uncertain about specific bots. As an example, User-agent: would apply to all crawlers, allowing you to manage visibility across the board. However,always pair it with clear rules,such as Disallow: /private/,to effectively guide bots on areas you want to keep under wraps. Additionally, don’t forget the importance of validating your file. A syntax error can lead to unexpected results, possibly exposing sensitive areas or unintentionally blocking essential content from being indexed. Using online validation tools ensures your robots.txt file operates as intended. Moreover, employing a well-structured approach—such as categorizing directives by user agent—can greatly enhance readability and ease of updates. Consider a layout like this:
| User-Agent | Disallow |
|---|---|
| * | /private/ |
| Googlebot | /temp/ |
| Bingbot | /old-site/ |
This organized configuration not only streamlines your file but also serves as a swift-reference guide for anyone who may need to modify it in the future, ensuring that best practices are adhered to consistently.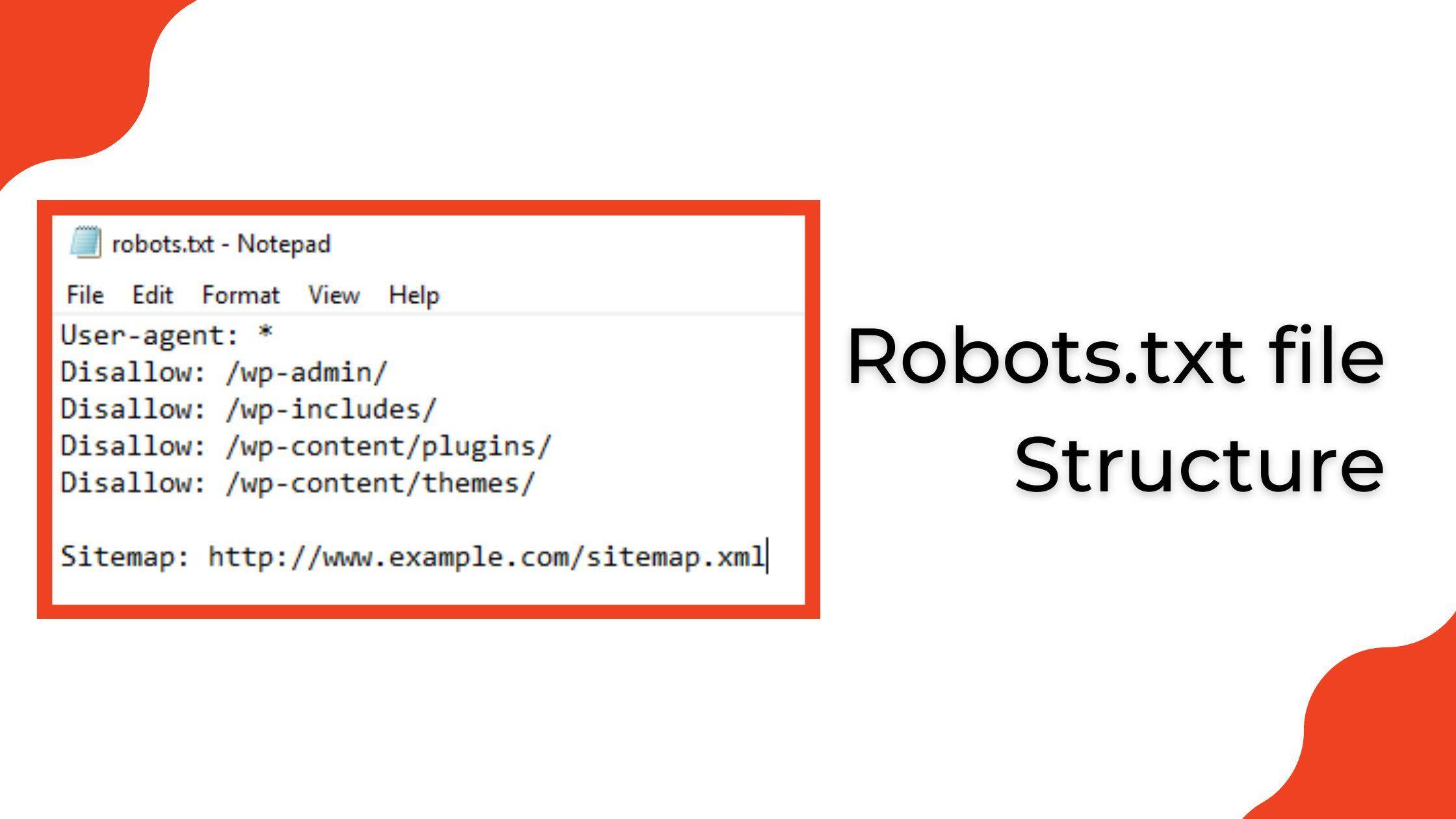
Common Pitfalls to Avoid When Using Robots.txt for SEO Optimization
When optimizing your website’s SEO, it’s easy to make mistakes with the robots.txt file that could hinder your visibility in search engines. One common pitfall is overly broad disallowing. many website owners inadvertently block access to important resources or directories,inadvertently keeping search engines from crawling pages that should be indexed. For example, if you disallow a crucial section where your key content lives, you could limit your site’s discoverability.Always ensure to regularly audit your robots.txt to prevent such missteps, focusing on specific paths rather than blanket bans. Another frequent error is failing to have a backup plan for your robots.txt. If changes are made that temporarily restrict crawlers, you might not notice until notable SEO damage occurs. To avoid this, consider maintaining a version history of your robots.txt file so you can easily revert to a previous state if something goes wrong. Additionally, testing your robots.txt directives using tools like Google Search Console can provide insights on how your adjustments impact crawling. By implementing these best practices, you can make sure that your robots.txt supports your overall SEO strategy without creating unnecessary barriers.
Q&A
Q&A: Unlocking Web Secrets: The role of Robots.txt Explained
Q1: what exactly is a robots.txt file? A1: A robots.txt file is a simple text file placed at the root of a website that instructs web crawlers and bots about which pages or sections of the site should be accessed and which should be off-limits. Think of it as the gatekeeper of your website, helping to manage and direct traffic from the digital web crawlers that roam the internet.
Q2: Why is the robots.txt file critically important for website owners? A2: The robots.txt file plays a crucial role in maintaining a website’s visibility and privacy. By controlling which areas are indexed by search engines,site owners can prioritize which content appears in search results,protect sensitive information,and improve server performance by limiting unnecessary crawler access. It’s a tool for safeguarding your online presence.
Q3: How do search engines interpret the robots.txt file? A3: When a search engine bot visits a website, it looks for the robots.txt file to understand the site owner’s preferences. The file uses specific directives like “Allow” and ”Disallow” to indicate which URLs should be crawled or ignored. Search engines generally respect these directives, treating them as guidelines to navigate the web with respect to the wishes of the website owner.
Q4: can using a robots.txt file harm my website’s SEO? A4: Yes, it can. If not configured properly, a robots.txt file can inadvertently block search engines from accessing important content that you want to be indexed.This could lead to lower visibility in search results and ultimately impact your site traffic. Therefore,it’s essential to regularly review and modify your robots.txt file as needed.
Q5: Are there any limitations to what a robots.txt file can do? A5: Absolutely. While it can instruct crawlers on which pages to avoid, it doesn’t guarantee that the specified pages won’t be accessed. Some bots, especially those with malicious intent, might disregard the rules outlined in your robots.txt file. So, it’s not a security measure but rather a set of guidelines for well-behaved crawlers.
Q6: How can I create or modify my robots.txt file? A6: Creating a robots.txt file is straightforward. You can do it using any text editor. Just ensure it’s named exactly “robots.txt” and is located at the root of your domain (e.g.,www.yoursite.com/robots.txt). There are also various online tools available that can help you generate the file according to your specifications. just remember to test your settings using Google’s Robots Testing Tool to ensure everything functions as intended.
Q7: What should I include in my robots.txt file? A7: The content of your robots.txt file will depend on your specific needs, but common entries include directives to block crawlers from accessing certain directories (like admin areas), allowing access to public pages, and specifying the location of your XML sitemap. Clarity and precision are key!
Q8: Is there a way for me to see if my robots.txt file is effective? A8: Yes! Various webmaster tools provided by search engines, such as Google Search Console, allow you to check how your robots.txt file is functioning. You can also monitor your site’s crawl errors and indexation levels to ensure that your directives are being followed and that you’re not unintentionally blocking essential content.
Q9: Can my website benefit from not having a robots.txt file at all? A9: Technically, yes. If you launch a new website and have no sensitive content to protect, not having a robots.txt file means you’re delegating crawling access freely. However, this approach can be risky, as it might allow unwanted bots to overload your server. A balanced approach with a thoughtfully designed robots.txt could be your best bet for optimal web management and maintenance.
Q10: What final advice can you offer for managing a robots.txt file? A10: Approach your robots.txt file as a dynamic instrument rather than a static text. Regularly review and update it according to your site’s structure and needs. Stay informed of changes in search engine guidelines and best practices to ensure that your file continues to serve its purpose effectively. Clear, informed choices today will pave the way for a more organized digital footprint tomorrow. — This Q&A provides an engaging and informative overview of the robots.txt file, equipping readers with the knowledge needed to better understand its importance in the digital landscape.
In Conclusion
the humble robots.txt file might seem like a simple text document, but its impact on the web is anything but trivial. As the gatekeeper of content accessibility, it plays a crucial role in shaping the way search engines interact with your website. By understanding and harnessing its capabilities, webmasters can not only protect sensitive data and optimize their site’s crawling efficiency but also strategically guide search engines toward their most valuable content. As we navigate the ever-evolving landscape of the internet, the insights gained from unlocking the secrets of robots.txt will empower you to make informed decisions that enhance your online presence.Whether you’re a seasoned developer or just beginning your digital journey, embracing the nuances of this powerful tool can lead to a more harmonious relationship between your site and the vast world of search engines.So, as you move forward, remember: in the realm of web growth, even the smallest file can unlock great potential. Happy optimizing!